Mengenal berbagai format file Next Generation Sequencing
Oleh Agus Wibowo

Daftar isi
- Pendahuluan
- Apa itu read, mate, dan coverage?
- FASTA & FASTQ: Format dasar NGS dan kualitasnya
- SAM & BAM: Dari read ke posisi di genom
- GFF/GTF & BED: Menyematkan makna pada genom
- VCF: Menyimpan informasi variasi genetik
- SRA: Gudangnya data NGS dunia
- Memahami format = Menguasai analisis
Catatan: Dalam tutorial ini, kita akan bekerja menggunakan pemrograman Bash dan R dalam lingkungan Linux. Anda dapat menggunakan VS code baik untuk membuat script R maupun menjalankan script Bash tersebut via terminal.
Pendahuluan
Bayangkan kita baru saja mendapatkan data hasil sekuensing dari laboratorium. Dan ngebatin: “Wah, sebentar lagi saya bisa tahu gen apa yang rusak atau SNP apa yang unik.” Tapi, begitu buka foldernya… jeng jeng kita dihadapkan dengan berbagai file berakhiran .fastq, .bam, .gff, .vcf, dan entah apa lagi. “mumet wes” 😵💫
Yup, dunia Next-Generation Sequencing (NGS) memang penuh dengan format file yang bagi pemula bisa sangat membingungkan, berukuran besar, dan bahkan diantaranya tidak bisa dibaca. Tapi jangan khawatir, setiap format punya fungsinya sendiri dan punya cara unik dalam penangananya. Seperti alat-alat di toolbox, mereka bekerja bersama untuk menjawab pertanyaan besar di biologi molekuler: variasi genetik, ekspresi gen, struktur genom, dan banyak lagi.
Jadi dalam materi ini, kita akan berkenalan dengan “bahasa” NGS: format file yang menjadi jembatan antara data mentah dan hasil analisis ilmiah.
Apa itu read, mate, dan coverage?
Sebelum terjun lebih jauh, mari kita luruskan beberapa istilah kunci:
-
Read - adalah potongan sekuens DNA hasil dari satu kali pembacaan oleh mesin sekuenser.
-
Mate - mengacu pada pasangan read dalam paired-end sequencing; satu dari ujung 5’, satunya lagi dari 3’.
-
Fragment - adalah molekul DNA asli yang disekuens.
-
Coverage - adalah ukuran seberapa dalam sebuah lokasi pada genom dibaca ulang oleh read.

Rumus coverage:
\[\text{Coverage} = \frac{L \times N}{G}\]di mana:
𝐿 = panjang read,
𝑁 = jumlah read,
𝐺 = ukuran genom.
Misalnya, jika kita punya 30 juta read, masing-masing sepanjang 100 bp, dan genomnya 3 miliar bp, maka coveragenya:
\[\frac{100 \times 30\,000\,000}{3\,000\,000\,000} = 1X\]Artinya, rata-rata tiap posisi hanya dibaca sekali dan terlalu dangkal (low depth) untuk analisis varian, misalnya.
FASTA & FASTQ: Format dasar NGS dan kualitasnya
Format FASTA adalah format berbasis teks untuk merepresentasikan sekuens nukleotida atau peptida, di mana nukleotida atau asam amino direpresentasikan menggunakan kode satu huruf. Kesederhanaan format FASTA membuatnya mudah dimanipulasi dan diurai menggunakan alat pemrosesan teks dan bahasa skrip seperti R, Python, Ruby, dan Perl.
Setiap sekuens dalam format FASTA dimulai dengan baris deskripsi tunggal, diikuti oleh baris-baris data sekuens. Baris deskripsi, yang sering disebut sebagai “defline”, dimulai dengan simbol “>” untuk membedakan antar data sekuens. Defline biasanya berisi pengidentifikasi unik dan informasi tentang sekuens tersebut.
Contoh format FASTA sederhana:
>NM_001276760.1 Homo sapiens tumor protein p53 (TP53), transcript variant 1, mRNA
GTGGAGTATTTGGATGACAGAAACACTTTTCGACATAGTGTGGTGGTGCCCTATGAGCCGCCTGAGG
TTGGCTCTGACTGTACCACCATCCACTACAACTACATGTGTAACAGTTCCTGCATGGGCGGCATGAA
CCGGAGGCCCATCCTCACCATCATCACACTGGAAGACTCCAGTGGTAATCTACTGGGACGGAACAGC
Meskipun sangat sederhana, FASTA tidak memiliki informasi tentang kualitas sekuens atau metadata lainnya yang sangat penting untuk analisis lebih lanjut. Nah, disinilah FASTQ berperan.
Format FASTQ adalah format standar berbasis teks untuk menyimpan sekuens DNA dan skor kualitas yang sesuai dari NGS. Setiap sekuens pembacaan terdiri dari empat baris.
Contohnya:
@HWI-K00288_BSF_0436:4:1101:10003:10669
GTGGAGTATTTGGATGACAGAAACACTTTTCGACATAGTGTGGTGGTGC
+
#4!DBDDDHFHFFHIGHIII
Pada contoh di atas,
- Baris pertama adalah identifier sekuens yang dimulai dengan ‘@’. Identifier ini sering berisi informasi tentang instrumen sekuensing, posisi flow cell, dan koordinat cluster.
- Baris kedua adalah sekuens DNA itu sendiri.
- Baris ketiga dimulai dengan ‘+’ dan berfungsi sebagai pemisah.
- Baris keempat berisi skor kualitas untuk setiap basa dalam sekuens, yang direpresentasikan sebagai karakter ASCII.
Proses inferensi basa (A, C, G, atau T) pada posisi spesifik dari fragmen DNA yang disekuensing selama proses sekuensing disebut base calling. Perlu dicatat bahwa, platform sekuensing tidaklah sempurna dan kesalahan dapat terjadi selama proses sekuensing ketika mesin mencoba menginferensikan basa dari setiap sinyal yang diukur. Untuk semua platform, kekuatan sinyal dan fitur karakteristik lainnya diukur dan diinterpretasikan oleh software base caller. Kesalahan mempengaruhi data sekuens secara langsung dan membuatnya kurang dapat diandalkan. Oleh karena itu, penting untuk mengetahui probabilitas kesalahan tersebut agar pengguna dapat mengetahui kualitas data sekuens mereka dan dapat mencari cara untuk menangani kesalahan kualitas tersebut.
Sebagian besar platform dilengkapi dengan program base calling yang memberikan skor kualitas Phred untuk mengukur akurasi setiap basa yang dipanggil. Skor kualitas Phred (Q-score) ini dapat mengubah probabilitas kesalahan pemanggilan basa menjadi skor integer yang mudah diinterpretasikan.
Skor Phred didefinisikan sebagai:
\[Q = -10 \cdot \log_{10}(p)\]Dimana $p$ adalah probabilitas kesalahan pemanggilan basa yang diestimasi oleh software caller.
Skor kualitas Phred diencode menggunakan karakter ASCII tunggal. Semua karakter ASCII memiliki angka desimal yang terkait dengannya. Encoding ini memungkinkan penyimpanan nilai kualitas yang kompak dalam format teks.
Skor Q yang lebih tinggi menunjukkan probabilitas kesalahan yang lebih kecil dan skor Q yang lebih rendah menunjukkan kualitas basa yang rendah yang lebih mungkin bahwa basa tersebut dipanggil secara salah. Misalnya, skor kualitas 20 menunjukkan tingkat kesalahan 1 dalam 100, yang sesuai dengan akurasi panggilan 99%. Secara umum, skor Q 30 dianggap sebagai tolok ukur yang menunjukkan akurasi panggilan 99,9%.
SAM & BAM: Dari read ke posisi di genom
SAM (Sequence Alignment/Map format), merupakan file yang kita dapatkan setelah memetakan file fastq ke genom referensi. Isi dari file ini memiliki 2 bagian utama:
-
Header (opsional), dimulai dengan
@ -
Alignment section: 11 kolom wajib + kolom opsional
Karena file SAM sangatlah besar, biasanya tools alignment mengkompresinya ke format yang lebih sederhana. Dalam hal ini adalah BAM, yang merupakan versi Biner (0 1) dari SAM yang lebih sederhana, sekaligus bentuk standar untuk menyimpan dan mendistribusikan data alignment sekuens. Format ini digunakan secara luas dalam alur kerja NGS, terutama untuk visualisasi dan analisis lebih lanjut seperti variant calling.
Namun, file berformat .bam tidak dapat dibuka secara langsung dengan text editor, harus menggunakan tools seperti Samtools dari Conda-Python. Jika kita menggunakan samtools dengan perintah di terminal bash misalnya.
# bash
samtools view data/normal.bam | head -n5
Catatan: Anda bisa mendownload contoh file .bam di sini melalui
wget https://www.bowo.digital/assets/data/normal.bam
Maka output yang dihasilkan akan sangat panjang. Alternatifnya, kita bisa menggunakan GenomicAlignments dari R-Bioconductor dan menspesifikasikan kolom informasi apa yang diinginkan, dengan menulis script di VScode sebagai berikut:
# r
# install Rsamtools dan GenomicAlignments
if (!requireNamespace("GenomicAlignments", quietly = TRUE))
BiocManager::install(c("GenomicAlignments", "Rsamtools"))
library(Rsamtools)
library(GenomicAlignments)
# path file
file_path <- "data/normal.bam"
# menentukan parameter informasi. Anda bisa menambahkan atau mengurangi parameter, misalnya "seq" dan "qual"
param <- ScanBamParam(what=c("flag", "pos", "mapq"))
# membaca file BAM dengan parameter
bam <- readGAlignments(file_path, param = param)
# mengkonversi ke data frame
bam_df <- as.data.frame(bam)
# menampilkan 5 baris pertama
head(bam_df, 5)
Berikut adalah contoh isi dari file .bam.
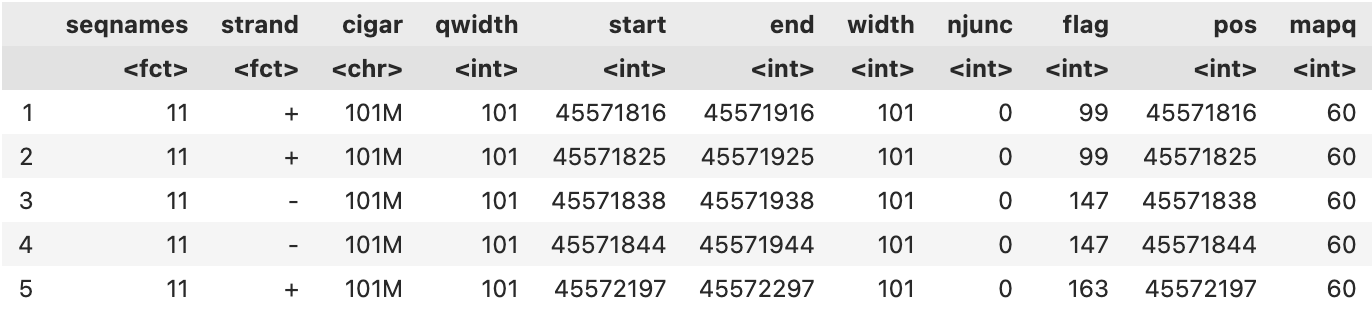
File .bam pada dasarnya memiliki 11 parameter, diantaranya:
| Kolom | Parameter | Tipe Data | Deskripsi Singkat |
|---|---|---|---|
| 1 | QNAME | String | Nama dari kueri atau read (template) |
| 2 | FLAG | Integer | Nilai bitwise yang menjelaskan status pemetaan read |
| 3 | RNAME | String | Nama sekuens referensi tempat read dipetakan |
| 4 | POS | Integer | Posisi paling kiri (berbasis 1) dari pemetaan pada referensi |
| 5 | MAPQ | Integer | Nilai kualitas pemetaan |
| 6 | CIGAR | String | String CIGAR yang menunjukkan cara read dipetakan ke referensi |
| 7 | RNEXT | String | Nama referensi pasangan read berikutnya (mate) |
| 8 | PNEXT | Integer | Posisi pasangan read berikutnya pada referensi |
| 9 | TLEN | Integer | Panjang fragmen yang diamati (template length) |
| 10 | SEQ | String | Urutan nukleotida dari segmen read |
| 11 | QUAL | String | Kualitas basis dalam format ASCII (Phred+33) |
Selain ukuran yang lebih sederhana, format file BAM memiliki akses yang lebih cepat ke data karena indeksing. File BAM dapat diindeks menggunakan file indeks (*.bai), yang memungkinkan program untuk melompat langsung ke bagian tertentu dari file BAM tanpa membaca semua sekuens.
GFF/GTF & BED: Menyematkan makna pada genom
GFF (General Feature Format) dan GTF (Gene Transfer Format) merupakan file anotasi genom untuk menggambarkan fitur genom seperti gen, ekson, intron, dan elemen fungsional lainnya. Strukturnya tab-delimited, dengan kolom ke-9 menyimpan atribut seperti gene_id dan transcript_id.
Supaya lebih mudah, kita bisa menggunakan data genom dari Turbot (Scophthalmus maximus).
Pertama download file gtf dari NCBI dengan menggunakan wget kemudian dekompresi dengan gunzip.
# bash
# download file gtf
wget https://ftp.ncbi.nlm.nih.gov/genomes/all/GCF/022/379/125/GCF_022379125.1_ASM2237912v1/GCF_022379125.1_ASM2237912v1_genomic.gtf.gz
# dekompresi dengan gunzip
gunzip GCF_022379125.1_ASM2237912v1_genomic.gtf.gz
Observasi struktur file GTF dengan head
# bash
head GCF_022379125.1_ASM2237912v1_genomic.gtf
Ini akan menampilkan:
-
Versi GTF: 2.2
-
Genome build: ASM2237912v1, berasal dari Scophthalmus maximus (turbot).
-
Akses referensi NCBI: GCF_022379125.1
-
Anotasi dilakukan oleh NCBI menggunakan pipeline Gnomon (algoritma prediksi gen otomatis).
Dengan fitur anotasi yaitu:
-
Gen:
Misalnya:
fblNC_061515.1 Gnomon gene 6189 13235 . + . gene_id "fbl"; ...Dimana Gen ini berada di kromosom/scaffold NC_061515.1, dengan panjang dari posisi 6189 sampai 13235 di strand plus (+) dan merupakan protein-coding gene
-
Transkrip
Misalnya:
XM_035607005.2NC_061515.1 Gnomon transcript 6189 13235 . + . gene_id "fbl"; transcript_id "XM_035607005.2"; ...Transkrip ini mencakup keseluruhan gen
fbldan memiliki bukti kuat dari RNA-seq dan EST/Protein homologi. Produk dari transkrip ini adalah fibrillarin, protein penting dalam pembentukan ribonukleoprotein nukleolus (nucleolar ribonucleoprotein) -
Ekson-ekson Transkrip
Setiap ekson diberi anotasi terpisah, menunjukkan struktur ekson dari transkrip tersebut, misalnya:
Ekson 1: 6189–6345
Ekson 2: 7987–8139
Ekson 3: 8343–8492
Ekson 4: 8933–9027
Masing-masing baris menyatakan bahwa keempat ekson ini merupakan bagian dari transkrip
XM_035607005.2dari genfbl, dan semuanya mendukung ekspresi mRNA fibrillarin.
Untuk melihat berapa banyak anotasi, kita bisa menggunakan perintah wc -l yang pada dasarnya hanya menampilkan berapa jumlah baris dalam file GTF
# bash
wc -l GCF_022379125.1_ASM2237912v1_genomic.gtf
Ini akan memberikan output:
1722738 GCF_022379125.1_ASM2237912v1_genomic.gtf
Kita juga bisa melihat semua fitur dalam file GTF dengan perintah dasar grep
# bash
grep -v "^#" GCF_022379125.1_ASM2237912v1_genomic.gtf | cut -f3 | sort | uniq -c
Maka akan menampilkan:
727878 CDS
807421 exon
26628 gene
51090 start_codon
51048 stop_codon
58668 transcript
Di sisi lain, format BED (Browser Extensible Data) merupakan format yang dapat digunakan untuk visualisasi melalui tools seperti IGV (Integrative Genomics Viewer), sehingga dapat menampilkan secara visual prihal lokasi dalam genom. Kita dapat mengkonversi file GTF ke BED menggunakan bedtools.
# bash
# Konversi GTF ke BED
bedtools intersect -a GCF_022379125.1_ASM2237912v1_genomic.gtf -b GCF_022379125.1_ASM2237912v1_genomic.gtf -wa | awk '$3=="exon"{print $1"\t"$4-1"\t"$5"\t"$10"\t.\t"$7}' > outputBED.bed
Perintah tersebut mengekstrak ekson dari file GTF dan mengubahnya ke format BED 6 kolom. bedtools intersect mempertahankan semua baris asli, lalu awk memfilter hanya baris bertipe "exon" dan mengkonversi formatnya (termasuk mengubah posisi awal dari 1-based menjadi 0-based) sebelum menyimpan hasilnya ke file outputBED.bed.
Untuk visualisasi menggunakan IGV, akan saya siapkan tutorialnya dalam artikel terpisah.
VCF: Menyimpan informasi variasi genetik
VCF (Variant Call Format) berisi informasi tentang varian genetik seperti SNP, insertions/deletions (indels), dan varian struktural yang ditemukan pada posisi tertentu dalam genom referensi. Contoh file VCF anda bisa download di sini. Ini adalah data dari studi oleh Fraslin et al .(2023) tentang genomic selection untuk resistensi bakteri Flavobacterium columnare pada rainbow trout, dimana menggunakan SNP sebagai marker genetiknya.
Untuk melihat bagaimana struktur dari file VCF, kita akan menggunakan paket vcfR dan tidyverse di R.
# r
# install vcfR
if (!requireNamespace("vcfR", quietly = TRUE))
install.packages("vcfR")
# panggil library
library(vcfR)
library(tidyverse)
# Baca file VCF terkompresi
vcf <- read.vcfR("phased.vcf.gz")
# konversi ke data frame
vcf_df <- vcfR2tidy(vcf)
# melihat struktur data frame utama (informasi varian)
head(vcf_df$fix)
# melihat data genotipe
head(vcf_df$gt)
# Ringkasan statistik dasar
summary(vcf_df$fix)
# Hitung varian per kromosom
vcf_df$fix %>%
count(CHROM) %>%
arrange(desc(n))
Ketika kita menjalankan fungsi read.vcfR(), ini akan menghasilkan output sebagai berikut:
File attributes:
meta lines: 8
header_line: 9
variant count: 27907
column count: 2883
Meta line 8 read in.
All meta lines processed.
gt matrix initialized.
Character matrix gt created.
Character matrix gt rows: 27907
Character matrix gt cols: 2883
skip: 0
nrows: 27907
row_num: 0
Processed variant: 27907
All variants processed
Di sini, ada 2 output utama, yaitu jumlah sampel dan jumlah varian. Jumlah sampel terbaca sebanyak 2883 dengan varian (SNP) sebanyak 27.907
Konversi VCF oleh fungsi vcfR2tidy() akan menghasilkan beberapa objek (menggunakan head(vcf_df) untuk melihat objek-objek nya), yaitu:
fix-> Data frame yang berisi informasi posisi dan anotasi variangt-> Data frame yang berisi informasi genotipe untuk setiap sampel dan varian, terutama untuk data terfase, kolom gt_GT akan menunjukkan alel dari setiap kromosom.meta-> Data frame yang berisi metadata dari file VCF, misalnya informasi tentang sampel dan genom referensi.
SRA: Gudangnya data NGS dunia
SRA (Sequence Read Archive) adalah database bioinformatika dari NCBI (National Center for Biotechnology Information) yang menyediakan repositori publik untuk data sekuensing. SRA menggunakan format biner untuk menyimpan data sekuensing mentah dalam bentuk yang efisien dan terkompresi, memungkinkan penyimpanan dan distribusi data sekuensing dalam jumlah besar.
Memahami format = Menguasai analisis
Format file NGS itu bukan sekadar teknis, ia adalah bahasa data yang harus kita kuasai untuk bisa menggali wawasan biologis. Tiap format punya perannya. Kalau Anda ingin jadi bioinformatikawan yang andal, jangan hanya belajar cara menjalankan perintah, tapi pahami struktur dan makna datanya. Karena jawaban dari analisis bukan di tools-nya, tapi di interpretasi datanya.
— Sekian —