Quality control hasil sequencing
Oleh Agus Wibowo
Daftar isi
- Apa itu quality control dan mengapa penting?
- Mendownload data sekuen
- FASTQC dan MULTIQC
- Kenapa kualitas data sekuensing bisa jelek?
- Mengatasi data sekuensing berkualitas rendah dengan FASTP
Catatan: Dalam tutorial ini, kita akan bekerja menggunakan pemrograman Bash dalam lingkungan Linux. Anda dapat menggunakan VS code baik untuk melihat dan mengedit script maupun menjalankan script Bash tersebut via terminal.
Apa itu quality control dan mengapa penting?
Bayangkan Anda mengambil foto dengan kamera harga ratusan juta, tapi lensa yang digunakan berembun. Hasilnya? Gambar blur yang nyaris tak bisa dilihat. Begitu juga dengan data sekuensing DNA yang kualitasnya buruk—tak peduli seberapa canggih analisisnya, hasilnya tetap tidak akan optimal.
Next-Generation Sequencing (NGS) telah membuka jendela baru untuk mengintip rahasia genetik makhluk hidup. Dalam sekali eksperimen, jutaan fragmen DNA berhasil dibaca! Tapi jumlah besar ini tidak otomatis menjamin kualitas. Seperti memilah berlian dari kerikil, quality control (QC) menjadi langkah krusial untuk memastikan data yang kita analisis benar-benar berharga.
Mendownload data sekuen
Dalam tutorial ini, kita menggunakan data dari studi oleh Robledo et al. (2014) yang meneliti respons transkriptomik ikan turbot (Scophthalmus maximus) terhadap infeksi Enteromyxum scophthalmi, penyebab enteromikosis. Penelitian ini menganalisis perubahan ekspresi gen di ginjal, limpa, dan usus menggunakan RNA-seq berbasis Illumina HiSeq 2000.
Dataset lengkap dapat diakses melalui ENA (European Nucleotide Archive) dengan kode proyek PRJNA269386. Karena ukuran total data mencapai sekitar 27 GB, dalam tutorial ini kita hanya menggunakan satu file sequencing yaitu SRR1695153, yang berasal dari organ limpa. Setiap file ini telah dimodifikasi untuk keperluan edukasi, sehingga ukurannya menjadi lebih kecil (60 MB) dan lebih mudah diolah. Bagi yang tertarik mempelajari proses manipulasi data tersebut, kode lengkapnya dapat didownload di sini.
Buat forlder baru untuk menyimpan dan mendownload file FASTQ yang sudah dikompresi dengan gunzip dengan cara:
# bash
# buat folder baru
mkdir -p data_fastq/
# masuk ke direktori data_fastq/
cd data_fastq/
# download data SRR
wget https://huggingface.co/datasets/bowo1745/fastqc_data/resolve/main/SRR1695148_edit_R1.fastq.gz
wget https://huggingface.co/datasets/bowo1745/fastqc_data/resolve/main/SRR1695148_edit_R2.fastq.gz
# ubah akses ke read-only
chmod u-w *fastq.gz
Catatan: Setiap hasil sequencing yang menggunakan paired-end reads maka akan selalu memiliki 2 file reads (R1 dan R2) untuk setiap sampel.
FASTQC dan MULTIQC
Setalah data didownload dan pada terminal kita berada di direktori data_fastq/, maka langkah selanjutnya adalah menginstall tools FASTQC. FASTQC adalah tool yang digunakan untuk melakukan quality control awal terhadap data sequencing, dengan memberikan ringkasan visual mengenai kualitas base, adapter contamination, overrepresented sequences, dan metrik penting lainnya dalam file FASTQ. Sementara MULTIQC merupakan tools untuk membantu meringkas hasil dari FASTQC, sangat bermanfaat jika kita bekerja dengan banyak data sekuensing.
Install FASTQC melalui anaconda Python dengan langkah-langkah sebagai berikut:
# bash
# buat env khusus untuk QC data sequencing dengan nama misalnya: qc_sequencing
conda create --name qc_sequence python=3.11
# aktifkan env qc_sequencing
conda activate qc_sequencing
# install fastqc
conda install fastqc multiqc
Untuk melakukan quality control dengan FASTQC pada data FASTQ, cukup gunakan perintah berikut setelah membuat direktori baru untuk menyimpan file hasil QC.
# bash
# buat direktori hasil QC
mkdir -p fastqc
# jalankan fastqc
fastqc *.fastq.gz -o fastqc/
# jalankan multiqc
multiqc fastqc/ -o fastqc/
Catatan: Setiap perintah yang menggunakan simbol
*diikuti dengan jenis file, misalnya*.fastq.gzmaka perintah tersebut akan memproses semua file dengan format .fastq.gz. Teknik ini sangat bermanfaat jika kita ingin memproses banyak file dengan jenis file yang sama.
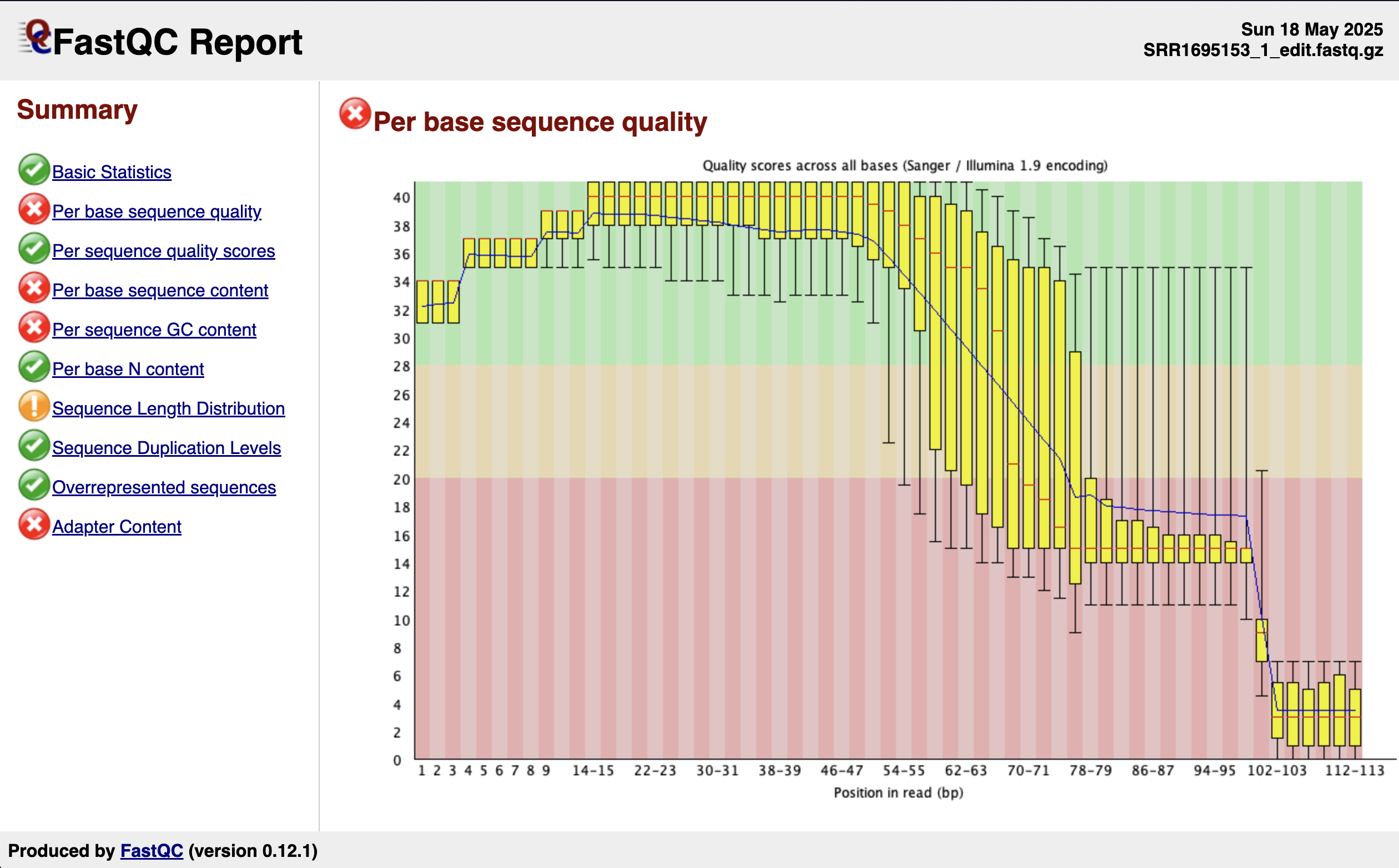
Setelah menjalankan FASTQC, di dalam folder fastqc/ akan terdapat dua jenis file: file berakhiran .html yang berisi laporan visual hasil analisis kualitas, dan file .zip yang berisi data mentah serta detail dari laporan tersebut. Untuk keperluan evaluasi, kita cukup membuka file .html menggunakan browser seperti Chrome atau Safari, maka akan tampil hasil seperti ini.
Anda juga bisa observasi langsung hasil MULTIQC yang dikerjakan untuk semua file FASTQ tanpa tanpa harus menjalankan semua perintah tadi dengan klik link berikut: Hasil MULTIQC
Interpretasi
Hasil FASTQC atau MULTIQC akan menampilakan beberapa hal diantaranya:
-
Basic Statistics
Menyediakan ringkasan umum data, seperti jumlah total reads, panjang reads, dan format kualitas encoding. Dalam data yang kita kerjakan, kedua sampel memiliki jumlah reads sekitar 300 ribu dengan kandungan GC stabil di 48%, menunjukkan komposisi basa yang normal.
-
Per base sequence quality
Menampilkan distribusi nilai kualitas (Phred score) untuk setiap posisi basa di dalam reads. Ini penting untuk melihat apakah kualitas menurun di bagian akhir reads.
-
Per sequence quality scores
Menunjukkan distribusi nilai kualitas rata-rata per read, untuk mengetahui apakah sebagian besar reads memiliki kualitas tinggi.
-
Per base sequence content
Memvisualisasikan proporsi basa A, T, G, dan C di setiap posisi. Pola tidak seimbang bisa mengindikasikan bias library preparation.
-
Per sequence GC content
Menampilkan distribusi kandungan GC dari semua reads dan membandingkannya dengan distribusi teoritis. Perbedaan signifikan bisa menandakan kontaminasi.
-
Per base N content
Menunjukkan persentase basa yang tidak dapat ditentukan (N) di setiap posisi basa.
-
Sequence Length Distribution
Memperlihatkan distribusi panjang reads. Idealnya, semua reads memiliki panjang yang seragam, terutama untuk data Illumina.
-
Sequence Duplication Levels
Menunjukkan proporsi reads yang terduplikasi. Duplikasi tinggi bisa terjadi karena over-amplifikasi atau bias library.
-
Overrepresented sequences
Mengidentifikasi reads yang muncul terlalu sering, yang dapat mengindikasikan kontaminasi atau adapter yang belum dibuang.
-
Adapter Content
Mengukur seberapa banyak urutan adapter yang masih tersisa dalam data. Tingginya konten adapter berarti trimming perlu dilakukan.
-
Kmer Content
Mengidentifikasi motif pendek yang muncul secara berlebih, yang bisa mengindikasikan kontaminasi atau bias teknis lainnya.
Pada data yang kita kerjakan, terutama yang ditampilkan pada tab “Status Check” dalam hasil MULTIQC, metrik seperti Per base sequence quality, Per base sequence content, Per sequence GC content, dan Adapter Content, berwarna merah, mengindikasikan ada MASALAH pada sekuen yang kita kerjakan.
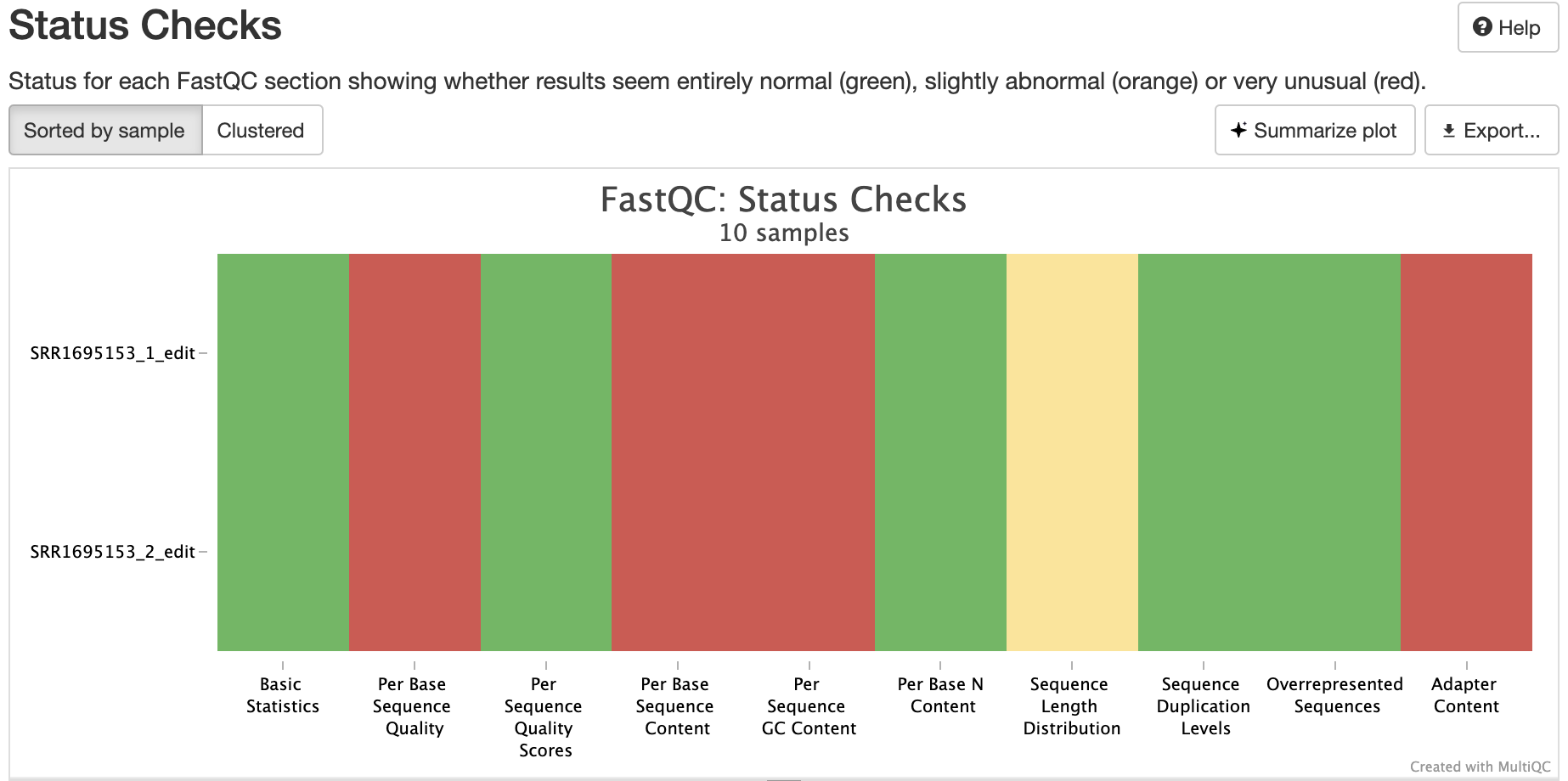
Kenapa kualitas data sekuensing bisa jelek?
Dalam proses sekuensing, salah satu masalah umum yang sering terjadi adalah masuknya sekuan adapter ke dalam hasil pembacaan. Hal ini biasanya disebabkan oleh potongan/fragmen DNA yang terlalu pendek dibandingkan panjang read yang dihasilkan oleh mesin sekuensing. Akibatnya, saat mesin membaca DNA dari kedua arah (paired-end), ia tidak hanya membaca urutan target, tetapi juga melampaui ujung fragmen dan mulai membaca bagian adapter. Seperti ditunjukkan pada gambar di bawah, di mana urutan adapter muncul dalam read karena panjang insert terlalu pendek.

Urutan adapter sendiri sebenarnya dibutuhkan pada tahap awal proses sekuensing, karena berfungsi sebagai tempat menempel primer dan memungkinkan amplifikasi serta pengikatan ke flow cell. Namun, apabila adapter tidak dihapus dari data mentah, keberadaannya dapat mengganggu proses downstream seperti pemetaan (mapping) atau anotasi. Oleh karena itu, langkah trimming adapter menjadi bagian penting dalam preprocessing data sekuensing, untuk memastikan hanya urutan biologis yang relevan yang dianalisis lebih lanjut.
Di sisi lain, pada sekuensing long-read seperti Oxford nanophore atau PacBio, tantangan QC berbeda dari teknologi short-read (Illumina). Panjang read menjadi metrik penting, karena read panjang cenderung lebih informatif, meski read yang sangat panjang bisa merupakan artefak. Proses penghapusan adapter juga lebih sulit akibat tingkat kesalahan yang tinggi. Nilai kualitas basa di ujung read sering rendah, dan tidak selalu mencerminkan panjang read, tidak seperti pada platform Illumina.
Mengatasi data sekuensing berkualitas rendah dengan FASTP
Dalam contoh data yang kita kerjakan, ada 3 masalah utama:
-
Kualitas Basis Menurun di Bagian Akhir.
Grafik Per base sequence quality menunjukkan bahwa kualitas sekuens menurun drastis setelah posisi ~70 bp, dan sangat buruk setelah 100 bp (banyak nilai di zona merah < Q20). Ini sering terjadi karena efisiensi pembacaan menurun seiring bertambahnya siklus sequencer.
-
Isi Adapter (Adapter Content)
Tanda silang merah di bagian Adapter Content mengindikasikan bahwa urutan adapter masih muncul dalam data.
-
Distribusi Panjang Read Variatif
Diberi tanda seru (!) untuk Sequence Length Distribution, artinya panjang read bervariasi dari 36 hingga 113 bp. Ini menandakan sekuen belum seragam atau memang berasal dari library dengan panjang fragment bervariasi.
Nah, di sinilah proses trimming berperan penting, untuk memastikan bahwa kita menggunakan data yang benar-benar siap analisis. Dalam tutorial ini, kita akan menggunakan FASTP untuk mengatasi memotong dan mengatasi masalah umum dalam data hasil sekuen. Dibandingkan dengan Trimmomatic, FASTP menawarkan proses yang lebih cepat, otomatis, dan user-friendly. Selain itu, FASTP juga mampu mendeteksi adapter secara otomatis dan menghasilkan laporan kualitas dalam format HTML, sehingga sangat efisien untuk analisis awal data sekuensing.
Install FASTP melalui anaconda:
# bash
# pastikan anda masih mengaktifkan env qc_sequencing
conda install fastp
# menampilkan dokumentasi FASTP
fastp --help
Ringkasnya, perintah umum FASTP jika kita menangani data jenis paired-end reads adalah;
# bash
fastp -i input.fastq -o output_cleaned.fastq \
-q 20 \
--cut_right \
--cut_right_mean_quality 20 \
--adapter_sequence=AGATCGGAAGAGC \
-l 36
Penjelasan perintah:
fastp -i input.fastq -o output_cleaned.fastq- Menjalankanfastpdengan input fileinput.fastqdan menyimpan hasil yang telah dibersihkan keoutput_cleaned.fastq.-q 20- Filter global untuk membatasi hanya base dengan nilai Phred ≥ 20 (artinya error rate ≤ 1%). Base yang nilainya lebih rendah bisa di-trim atau dibuang tergantung konteks pengaturannya.--cut_right- Mengaktifkan mode trimming dari sisi kanan (akhir) read. Ini berguna saat bagian ujung read menunjukkan penurunan kualitas, seperti yang terlihat pada data yang kita miliki--cut_right_mean_quality 20- Menentukan ambang kualitas rata-rata di ujung kanan yang digunakan untuk memutuskan kapan trimming harus berhenti. Jika rata-rata kualitas pada posisi tertentu < 20, maka bagian itu dan sesudahnya akan dipotong.--adapter_sequence=AGATCGGAAGAGC- Menentukan adapter sequence Illumina yang akan dicari dan dihapus dari read. Ini sangat penting karena sampel sekuens kita mengandung sisa adapter.-l 36- Menyaring hasil akhir agar hanya menyimpan read yang memiliki panjang minimal 36 bp. Sehingga read yang lebih pendek dari ini setelah trimming akan dibuang.
Untuk automatisasi proses trimming dengan FASTP serta menangani data yang mungkin banyak, saya sudah menyiapkan code bash yang bisa digunakan untuk menangani data paired-end apapun selama memiliki format file *_R1/R2.fastq.gz. Anda bisa download code bash nya di sini dan menjalankan perintah sebagai berikut:
# bash
chmod +x process_paired_fastq.sh
# jalankan proses autotrimming
bash process_paired_fastq.sh -i data_fastq/ -o fastq_ready/
Perintah di atas akan secara otomatis memproses file .fastq.gz yang berada di direktori data_fastq/ kemudian menyimpan hasilnya di dalam direktori fastq_ready/ meskipun anda belum membuat direktori ini sebelumnya. Secara default, script ini akan menjalankan perintah dari FASTP dengan jumlah thread pemrosesan sebanyak 4, nilai kualitas minimum 20, panjang minimum read 36, dan menggunakan AGATCGGAAGAGC sebagai sekuen adapter. Kemudian menjalankan FASTQC dan MULTIQC sekaligus.
Anda bisa melihat dokumentasi cara menggunakan script bash ini dengan menggunakan perintah --help
# bash
# menampilkan dokumentasi script
bash process_paired_fastq.sh --help
# menjalankan opsi custom misalnya: 8 threat, dengan nilai kualitas minimum 30, panjang minimum read 50, dan menggunakan AGATCGGAAGAGC sebagai adapter
bash process_paired_fastq.sh -i data_fastq/ -o fastq_ready/ -t 8 -q 30 -l 50 -a AGATCGGAAGAGC
Anda bisa lihat video demonstrasinya di bawah ini.
Setelah diperbaiki, hasil pada “Status Check” MULTIQC menjadi sedikit lebih baik, terutama untuk R2. Bisa dilihat di sini
— Sekian —